Chapter 2 数据导入
数据导入界面有许多研发人员的小巧思,不仅可以在导入界面全面预览数据,包括数据缺失情况及分类情况,还可以进行简单的预处理:
转换变量类型
变量重命名
剔除变量
……
2.1 导入数据集格式介绍
2.1.1 基本情况
目前网站支持导入数据格式为 .csv, .txt, .xls, .xlsx, .rds, .fst, .sas7bdat, .sav files,数据集大小不超过10M.
Excel格式的数据集可自建,也可基于SPSS导出;
CSV格式一般可以从excel导出或者基于SPSS导出;
初学者我建议从SPSS导出,因为SPSS具有固定的数据集格式,而EXCEL没有。
2.2 操作说明
2.2.1 Browse选入数据
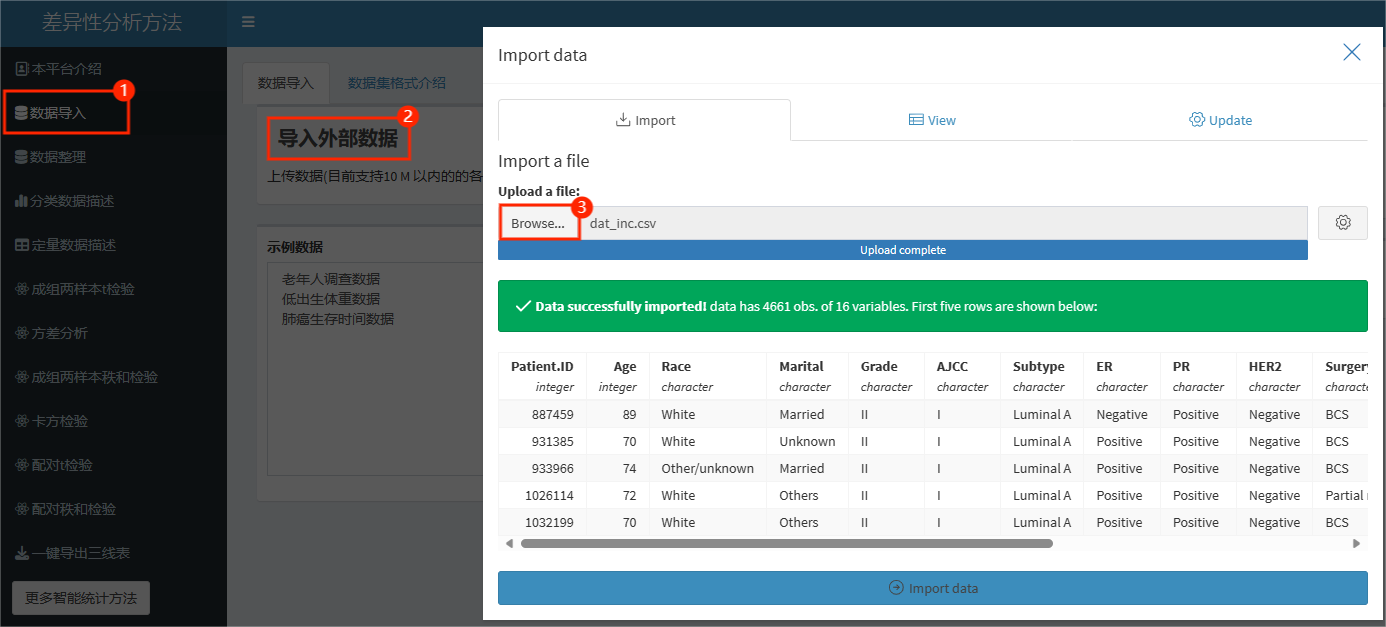
根据下方图示,依次点击“数据导入”——“导入外部数据”——“Browse...”,选入数据集后,指示框中就会出现数据概览了!
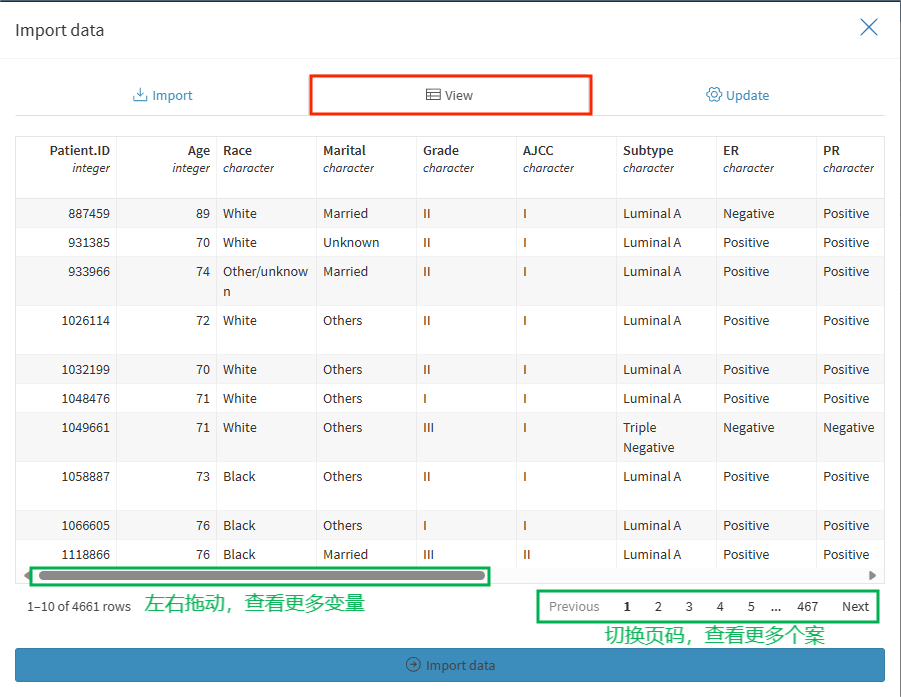
右侧有一个小小的工具栏,大家使用频率可能不高,这里进行一下简单的说明。

这里的n代表读取数据时需要跳过的行数,譬如说,变量名是从第二行开始的,那么这里的n就可以改作1,代表跳过首行读取数据
,NA代表缺失数据的表示方式,这里不建议大家更改,保留默认设置更有利于后面的分析
小数的分隔符,默认为”.”,如果数据导入过程中是其他表述方式,也可以在这里一键修改
编码为UTF-8,指使用UTF-8编码方式,这也是最常见的,其他还有UTF-16、UTF-16BE等

2.2.3 Update数据简单处理
update界面有许多关键要素,这里会逐一进行说明!
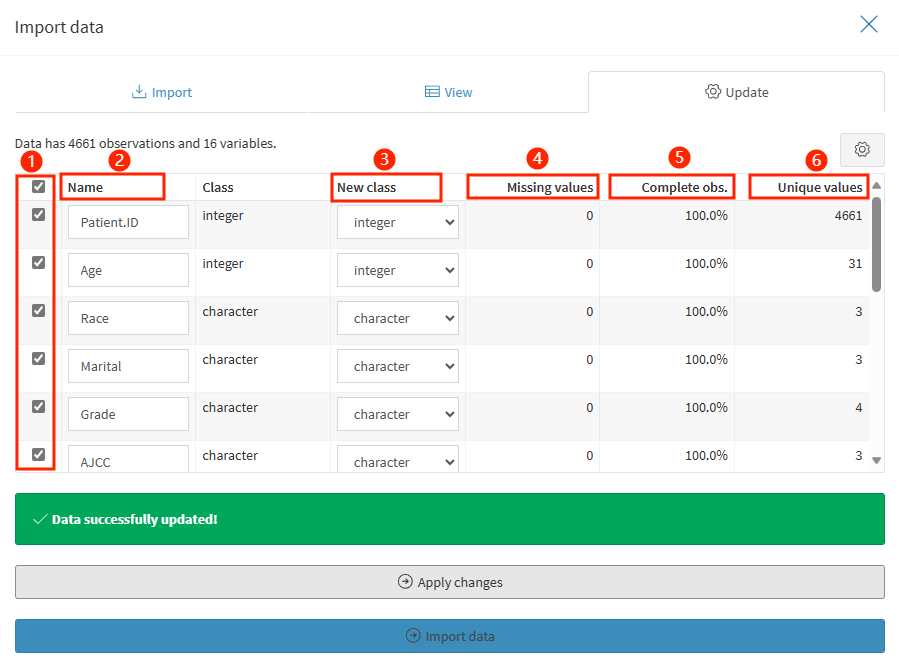
挑选需要分析的变量,譬如这里的“Patient.ID”,患者的ID在本次分析中用不到,为了简化数据,直接取消勾选,那么接下来的分析中就不会出现啦!
Name列,有的原始数据中变量名十分晦涩,这里可以直接在条目框中重命名进行修改。
New class列,相信了解一些R语言的朋友就会知道,R语言分析过程中变量的类型是有要求的,例如分类变量一定要因子化(factor),否则分类变量就会默认按照定量数据进行分析,这不是我们想要的。在这里就可以快速整理完毕!
character字符型:可用来表示定性变量,如”男性”,“白人”等文字资料,但在数据分析时,可能出现报错的情况,建议数据均转换为数字进行导入!
factor因子型:分类变量需要转为因子型,否则R语言无法识别将会按照定量数据进行分析
numeric数值型:将定量数据转换为数值型更有利于分析,可以显示小数
integer整数型:同样用于表述定量数据,但是无法显示小数
date与datetime:都是用于表述时间的数据类型,不同的是date仅能描述xx年xx月xx日,而datetime表述的时间更加精确可以到xx年xx月xx日xx时xx分xx秒,格式:YYYY-MM-DD HH:MM:SS。

Missing values列,缺失数据会在这一列显示,直观显示数据的缺失情况,在数据导入阶段,就对数据的缺失情况有一个总体的概览。
Complete obs列,该变量完整数据所占比例。
Unique values列,变量的全部分类,譬如说这个数据中Race为三分类数据,Marital为四分类数据,Age为定量数据因此显得分类很多有31种。
这里同样有一个小工具栏,也简单说明一下!
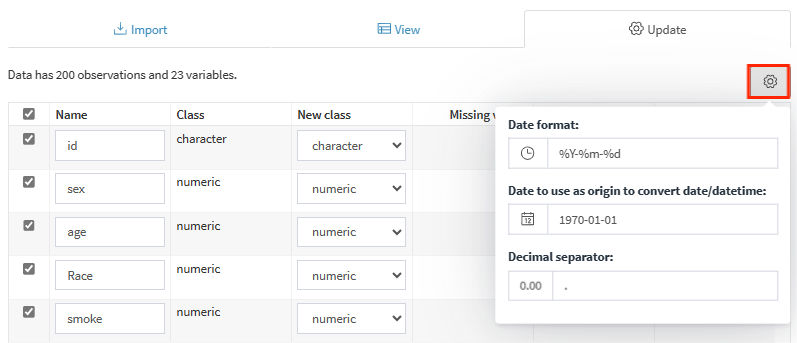
Date format:代表日期格式为 xxY(year) xxm(month) xxd(day)
用于转换date或者datetime的起始时间
小数的分隔符,默认为”.”
调整完毕后,点击”Apply changes”,保存更新,出现绿色”Data successfully updated”提示说明保存成功!
最后,点击”import data”,完成数据导入!